

In the era of information wars and mass disinformation, automatic content analysis systems are becoming an indispensable tool for fact-checkers and media researchers. In this article, we compare two common approaches to identifying manipulative content — classical natural language processing (NLP) methods and the latest technologies based on large language models (LLM).
As part of the research, a corpus of video content with the hashtag #беларусь from the TikTok social network was analyzed. The analysis period was from March 20 to April 21, 2025. Exolyt – TikTok Social Intelligence Platform was used for data collection. The titles, descriptions, and tags of the videos were analyzed. But the main interest is not the content itself, but how different technological approaches evaluate the same data.


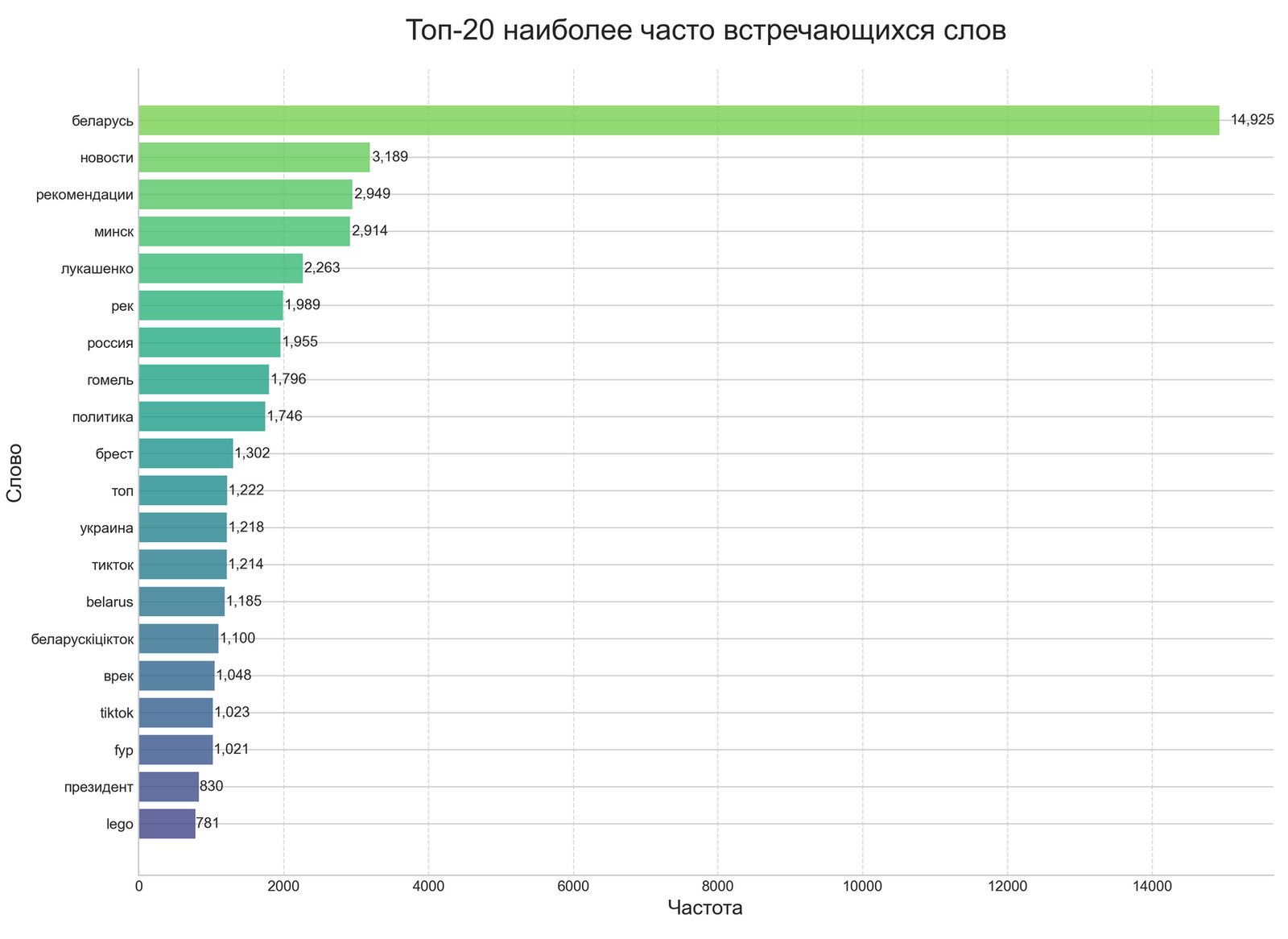
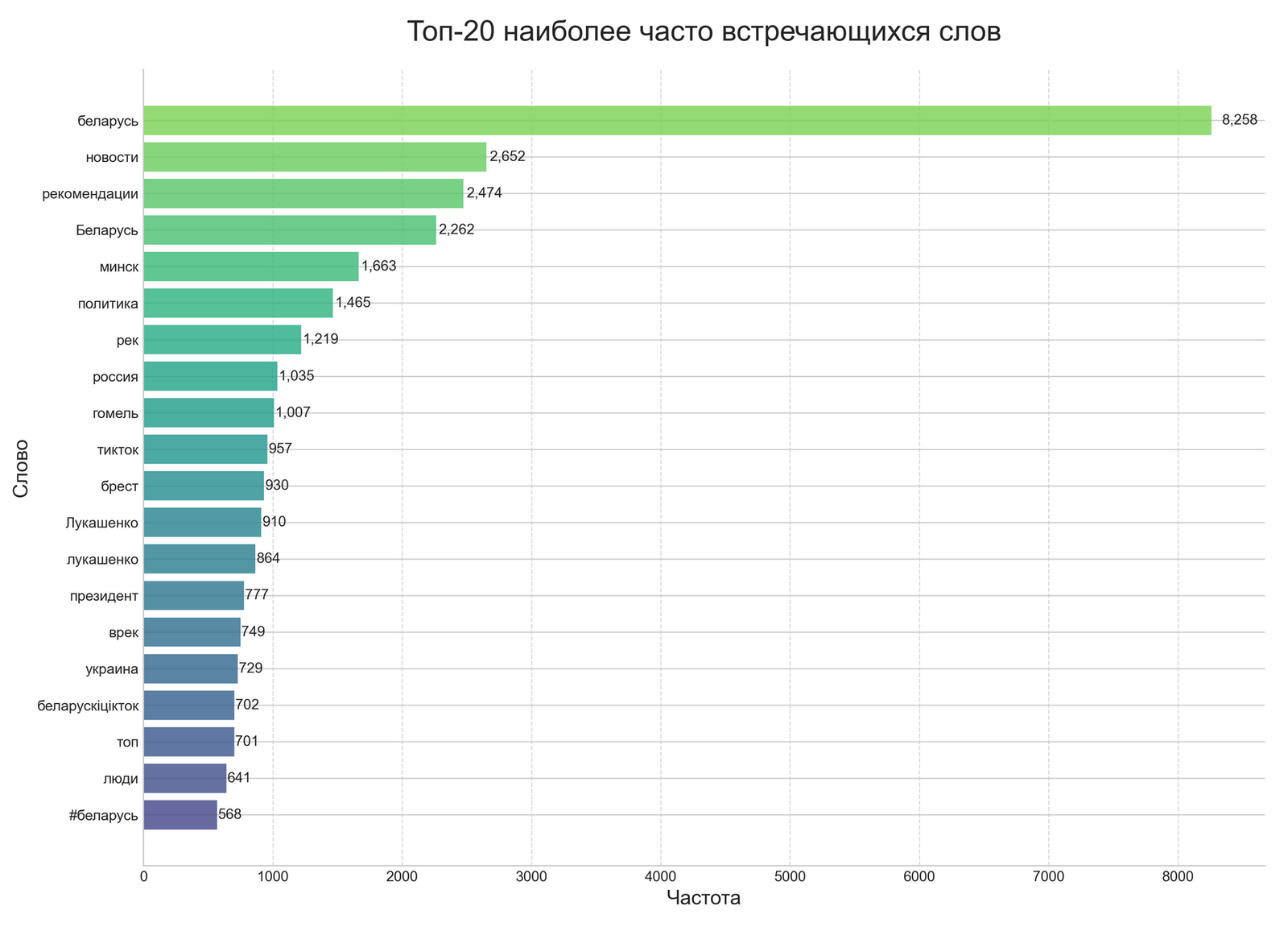

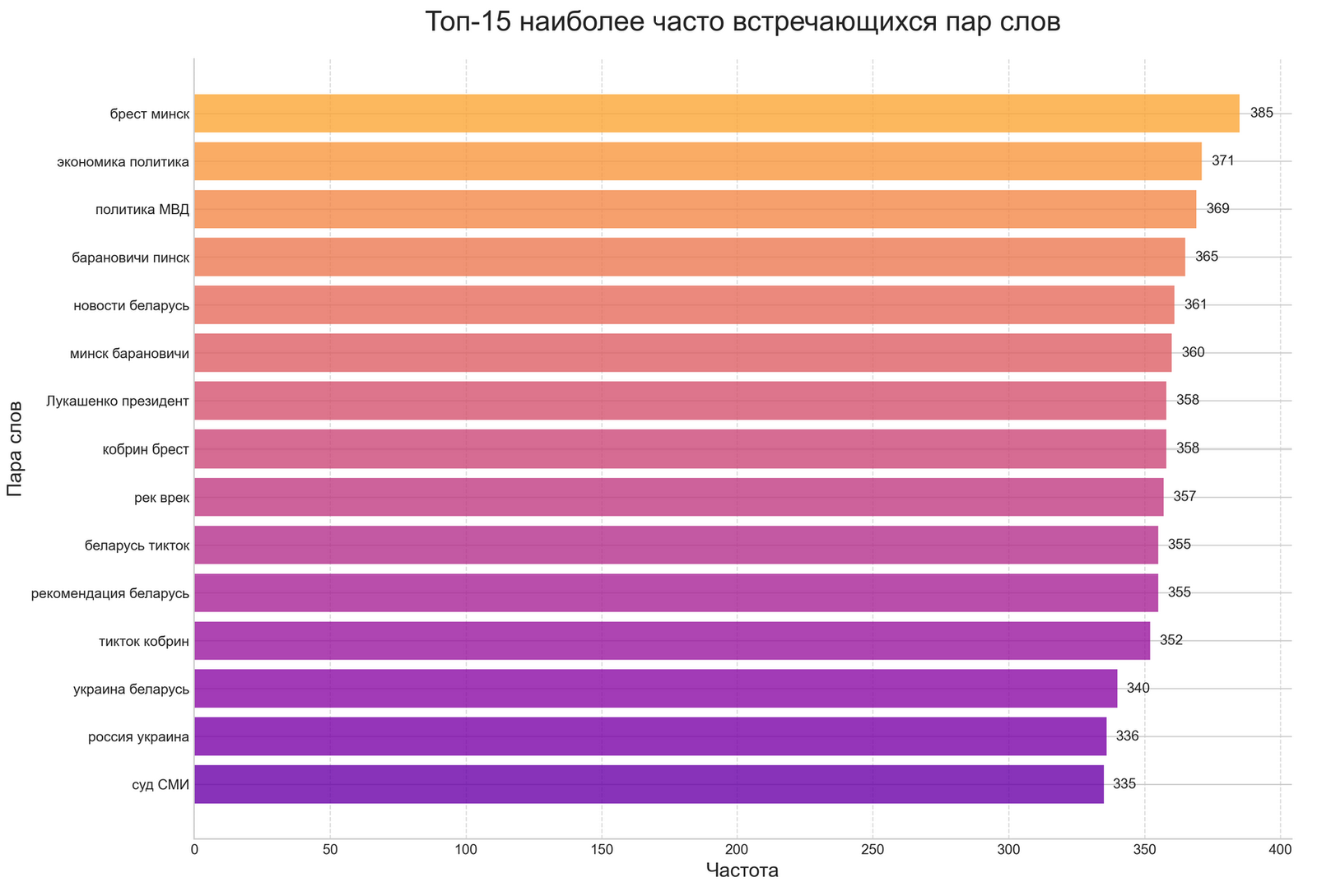





Interpretation of Results: What Did the Two Different Methods Show?
Such significant discrepancies in the results of the two methods require careful analysis and interpretation.
Different understanding of text “emotionality” is manifested in the fact that the NLTK approach determines emotional coloring based on the presence of specific marker words from a predefined dictionary, without taking into account the context of their use. The word “war” is automatically classified as negative, regardless of context, which leads to an overestimation of negativity in the analysis of political topics. The OpenAI approach evaluates emotional coloring based on a more complex understanding of the text, is able to distinguish nuances and shades of meaning in a specific context.
An example from our data corpus: “Belarus: regional news, political situation, analytical materials”. NLTK classifies this text as negative due to the presence of political topics, while OpenAI can classify it as neutral, considering the informational, rather than evaluative nature of the content.
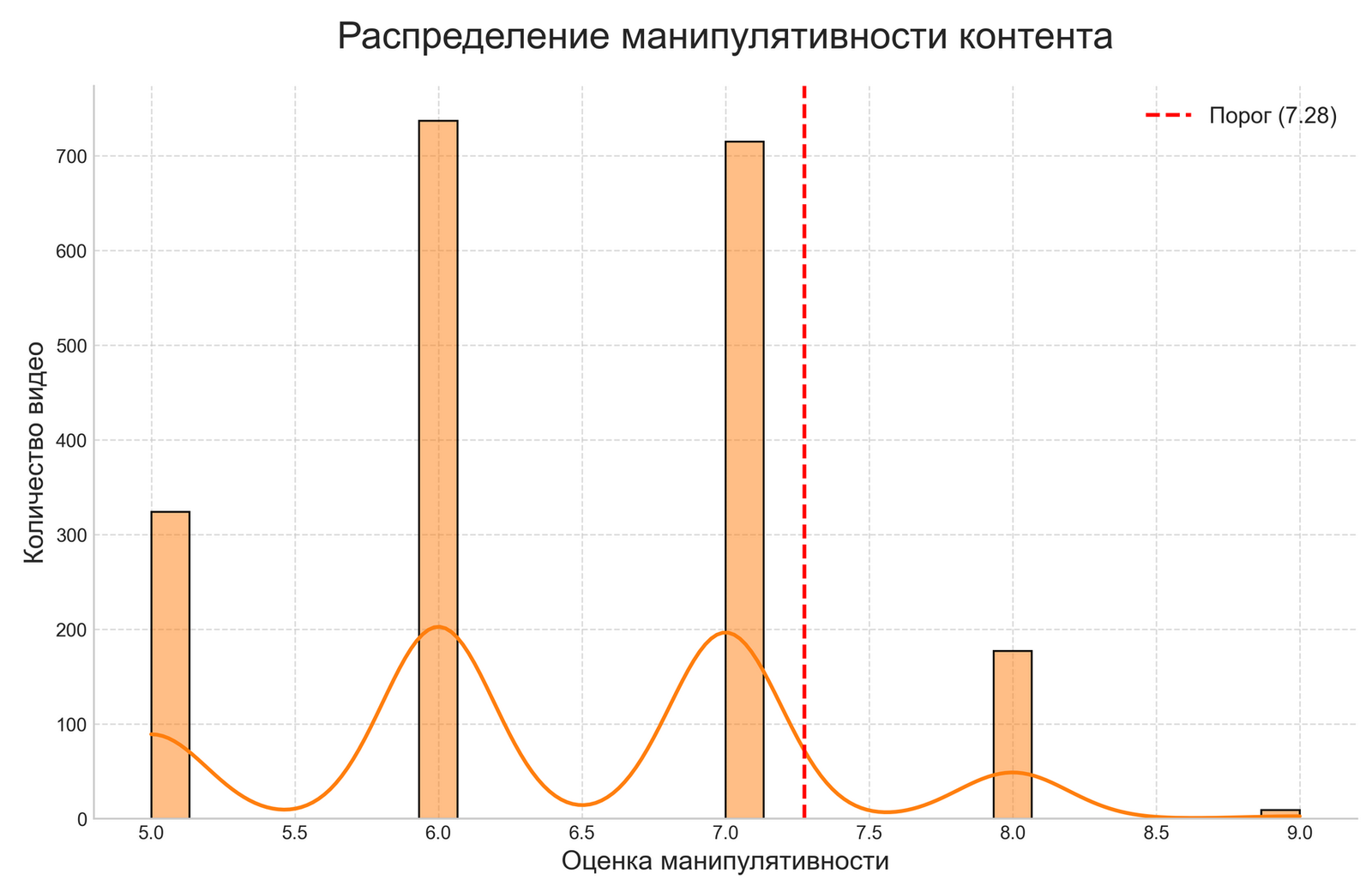
Different concepts of “manipulativeness” are manifested in the fact that the NLTK approach defines manipulativeness through a simplified mathematical formula based on the quantitative ratio of emotionally colored words. The OpenAI approach evaluates manipulativeness based on a more complex analysis that takes into account rhetorical techniques, logical structures, and other signs of manipulation that a simple dictionary approach may not capture.
The political context of content with the hashtag #беларусь plays a significant role in such a dramatic divergence of results. NLTK, relying on dictionaries of emotional markers, tends to classify political topics as negative due to frequently encountered terms related to conflicts, power, and confrontation. OpenAI, with a more developed understanding of context, is able to distinguish neutral informational coverage from emotionally colored propaganda.
Interpretation of Results: What Did the Two Different Methods Show?
Such significant discrepancies in the results of the two methods require careful analysis and interpretation.
Different understanding of text “emotionality” is manifested in the fact that the NLTK approach determines emotional coloring based on the presence of specific marker words from a predefined dictionary. The word “war” is automatically classified as negative, “victory” — as positive, regardless of context. The OpenAI approach evaluates emotional coloring based on a comprehensive understanding of the text, including context, subtext, and hidden meanings. The phrase “another brilliant victory” can be recognized as irony and classified as negative.
An example from our data corpus: “Belarus: regional news, political situation, analytical materials”. NLTK classifies this text as neutral, as it has no obvious emotional markers. OpenAI can classify it as potentially negative, considering the context of political news in the current situation.
Different concepts of “manipulativeness” are manifested in the fact that the NLTK approach defines manipulativeness through a mathematical formula based on the ratio of negative and positive words. This approach assumes that manipulative content is predominantly negative content. The OpenAI approach evaluates manipulativeness based on a complex understanding of rhetorical techniques, logical errors, emotional pressure, distortion of facts, and other signs of manipulation that may be present even in formally positive or neutral text.
The political context of content with the hashtag #беларусь may play a significant role in such a dramatic divergence of results. A large language model trained on a huge corpus of texts, including news and analytical materials, can “understand” the complex political context and capture hidden meanings and subtexts related to the coverage of the political situation in the region.
What This Means for Fact-checking and Media Literacy
The identified discrepancies between the two approaches have serious implications for the work of fact-checkers and media researchers.
Methodological challenges include the problem of the “gold standard”, that is, the question of which method is closer to the truth, and it is quite likely that the truth is somewhere in the middle or requires a fundamentally different approach; subjectivity of assessments, when even advanced algorithms reflect subjective ideas about what is considered manipulation and what is legitimate persuasion; contextual dependence, which manifests itself in the fact that the assessment of manipulativeness depends heavily on the cultural, social, and political context, which makes it difficult to create universal algorithms.
Based on our research, we recommend that fact-checking organizations apply triangulation of methods, using several different algorithmic approaches to verify the consistency of results; adjust threshold values, calibrating the threshold of “manipulativeness” based on expert assessment of a sample of content; implement human control, since automatic systems should act as a decision support tool for experts, not their replacement; take into account the strengths of different approaches, taking into account that the NLTK approach gives a more balanced assessment of emotional coloring, and the OpenAI approach can be useful for identifying hidden manipulative techniques; adapt technologies to the local context, developing specialized dictionaries of emotional markers for specific topics and languages; ensure transparency of methodology, publicly disclosing the analysis methods used and their limitations when publishing fact-checking results.
The results of our study emphasize the need to educate a wide audience on recognizing various types of manipulations that go beyond explicitly negative emotional coloring; developing critical thinking and media content analysis skills; understanding that automatic analysis systems, including advanced AI models, have their limitations and biases.
Technical Evaluation of Two Approaches: Cost, Scalability, Accessibility
For making informed decisions about technology implementation, it is important to consider not only their accuracy but also practical aspects of use.
In terms of cost and resources, the NLTK approach is completely free, uses only open-source software, works locally without internet connection, requires moderate computing resources, and processing 12,252 videos took about 20 minutes. The OpenAI approach requires payment for API requests (approximate cost of analyzing our corpus ~$100-150), depends on a stable internet connection, creates minimal load on local resources, and processing the same amount of data took about 1-2 hours, taking into account API delays.
In terms of scalability and performance, the NLTK approach easily scales to process large volumes of data, its performance can be increased through parallel processing, and processing speed is directly proportional to available computing resources. The OpenAI approach is limited by quotas and API speed, its scaling increases cost in proportion to the volume of data, requires request queue management and error handling.
Flexibility and customization in the NLTK approach is manifested in complete transparency and customizability, the ability to modify dictionaries of emotional markers, change tokenization algorithms and evaluation formulas, but requires expertise in Python and NLP for significant modifications. The OpenAI approach offers limited customization options through prompt engineering, the internal workings of the model are not transparent (black box), the model is regularly updated by the provider, which can affect results, but does not require deep technical expertise for basic use.
In terms of accessibility and infrastructure requirements, the NLTK approach works on any computer with Python, does not require specialized equipment, can be deployed in an isolated network, and is suitable for processing confidential data. The OpenAI approach requires a constant internet connection, data is sent to third-party servers, may be limited by geopolitical factors, and is not suitable for processing strictly confidential information.
Practical Application Scenarios: When Is Each Approach Better
Based on our comparative analysis, we can identify optimal usage scenarios for each approach.
The OpenAI approach is optimal for a more balanced assessment of the emotional coloring of content, especially when working with politically colored topics; for in-depth analysis of complex content, when investigating sophisticated information campaigns, for identifying hidden manipulations and subtexts, when working with content that requires understanding of cultural context; for organizations with limited technical expertise, when there are no in-house NLP specialists, when there is a need to quickly launch an analytical system.
The NLTK approach is optimal for primary screening of large volumes of data to identify potentially negative content that requires further analysis; for work in conditions of limited network access, in regions with unstable internet connection, in organizations with strict information security policies, when working with confidential or sensitive data; for creating specialized solutions when precise customization for a specific topic or language is required, when full control over the algorithm is needed, for integration into existing monitoring systems. It should be noted that this method tends to classify most political content as negative.
A hybrid approach is recommended for professional fact-checking organizations – using NLTK for primary identification of potentially problematic content, followed by deeper analysis using OpenAI for a more balanced assessment, culminating in expert evaluation for final conclusions and publications; for research centers and analytical agencies – comparative analysis of results from different approaches, combining quantitative and qualitative methods, developing new metrics and methodologies based on best practices from both approaches, in educational projects on media literacy.
A hybrid approach is recommended for professional fact-checking organizations – NLTK for primary screening and selection of suspicious content, OpenAI for in-depth analysis of selected materials, expert evaluation for final conclusions and publications; for research centers and analytical agencies – comparative analysis of results from different approaches, combining quantitative and qualitative methods, developing new metrics and methodologies based on best practices from both approaches.
Conclusion and Prospects for the Development of Automated Media Content Analysis
Our research clearly demonstrates that automated analysis of media content is at a crossroads of traditional algorithmic approaches and new possibilities of artificial intelligence. Each method has its strengths and weaknesses, and there is no perfect solution suitable for all tasks.
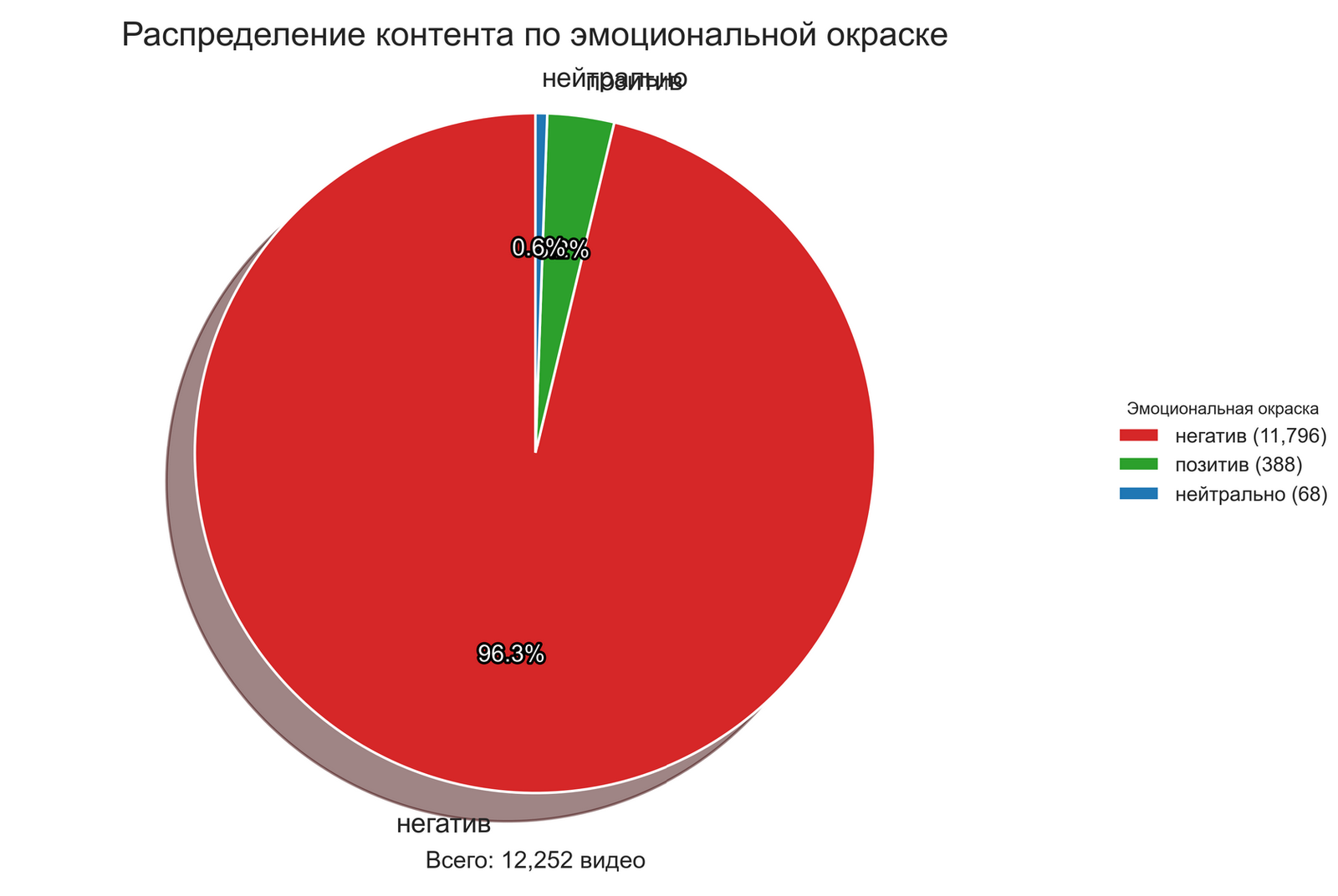
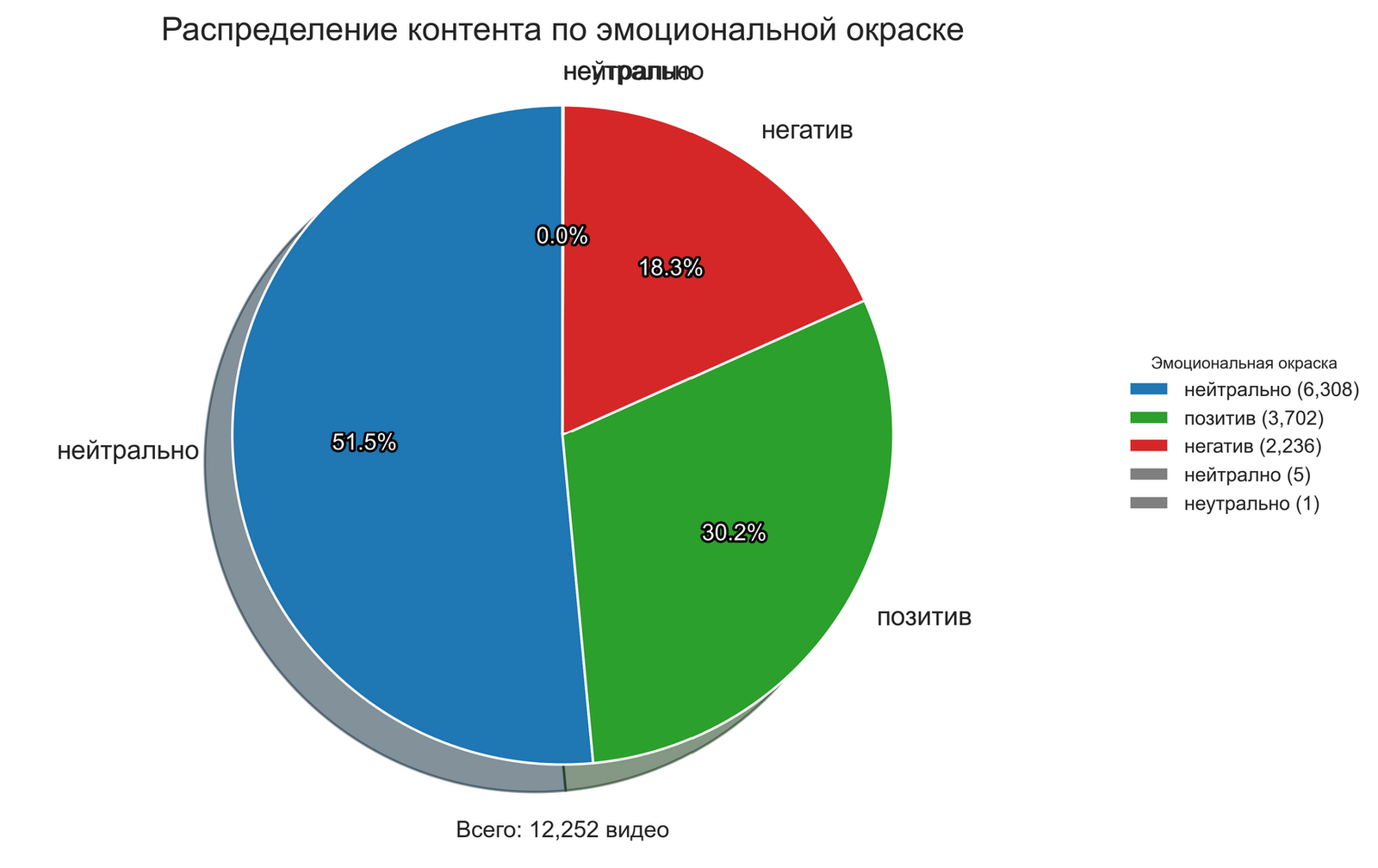
The dramatic difference in the results of evaluating the same data corpus by two different methods emphasizes the need for a critical attitude towards automated analysis tools. It is particularly illustrative that the NLTK method classified the vast majority of content (96.3%) as negative, while the OpenAI method gave a more balanced assessment with a predominance of neutral content (51.5%).
This discrepancy demonstrates how strongly the results of analysis can depend on the chosen method, which has serious implications for media space researchers and fact-checkers. When using automated systems for monitoring media content, it is necessary to be aware of the possible bias of algorithms and take it into account when interpreting results.
No algorithm can replace expert evaluation and critical thinking, but the competent application of technology can significantly increase the efficiency of fact-checkers and media researchers. The most productive approach seems to be combining different analysis methods with subsequent expert evaluation of results.
In the coming years, we are likely to see the development of several directions: specialized models for media content analysis, trained on examples of manipulative techniques; local versions of large language models that do not require sending data to external servers; interactive tools combining automatic analysis with expert evaluation; educational platforms using AI to teach citizens media literacy.
Regardless of technological progress, the key success factor will remain human expertise, critical thinking, and commitment to high ethical standards in combating disinformation and manipulation. Automated systems should be viewed as decision support tools, not as a replacement for expert evaluation.
This publication was developed by a research team under the leadership of Mikhail Doroshevich, PhD.







