

У эпоху інфармацыйных войнаў і масавай дэзынфармацыі аўтаматычныя сістэмы аналізу кантэнту становяцца незаменным інструментам для фактчэкераў і даследчыкаў СМІ. У гэтым артыкуле мы параўноўваем два распаўсюджаныя падыходы да выяўлення маніпулятыўнага кантэнту — класічныя метады апрацоўкі натуральнай мовы (NLP) і найноўшыя тэхналогіі на базе вялікіх моўных мадэляў (LLM).
У рамках даследавання быў прааналізаваны корпус відэакантэнту з хэштэгам #беларусь сацыяльнай сеткі TikTok. Аналізуемы перыяд з 20 сакавіка па 21 красавіка 2025. Для збору дадзеных выкарыстоўваўся Exolyt – TikTok Social Intelligence Platform. Аналізу падвергліся назвы, апісанні і меткі відэаролікаў. Але галоўны інтарэс уяўляе не змест кантэнту, а тое, як розныя тэхналагічныя падыходы ацэньваюць адны і тыя ж дадзеныя.


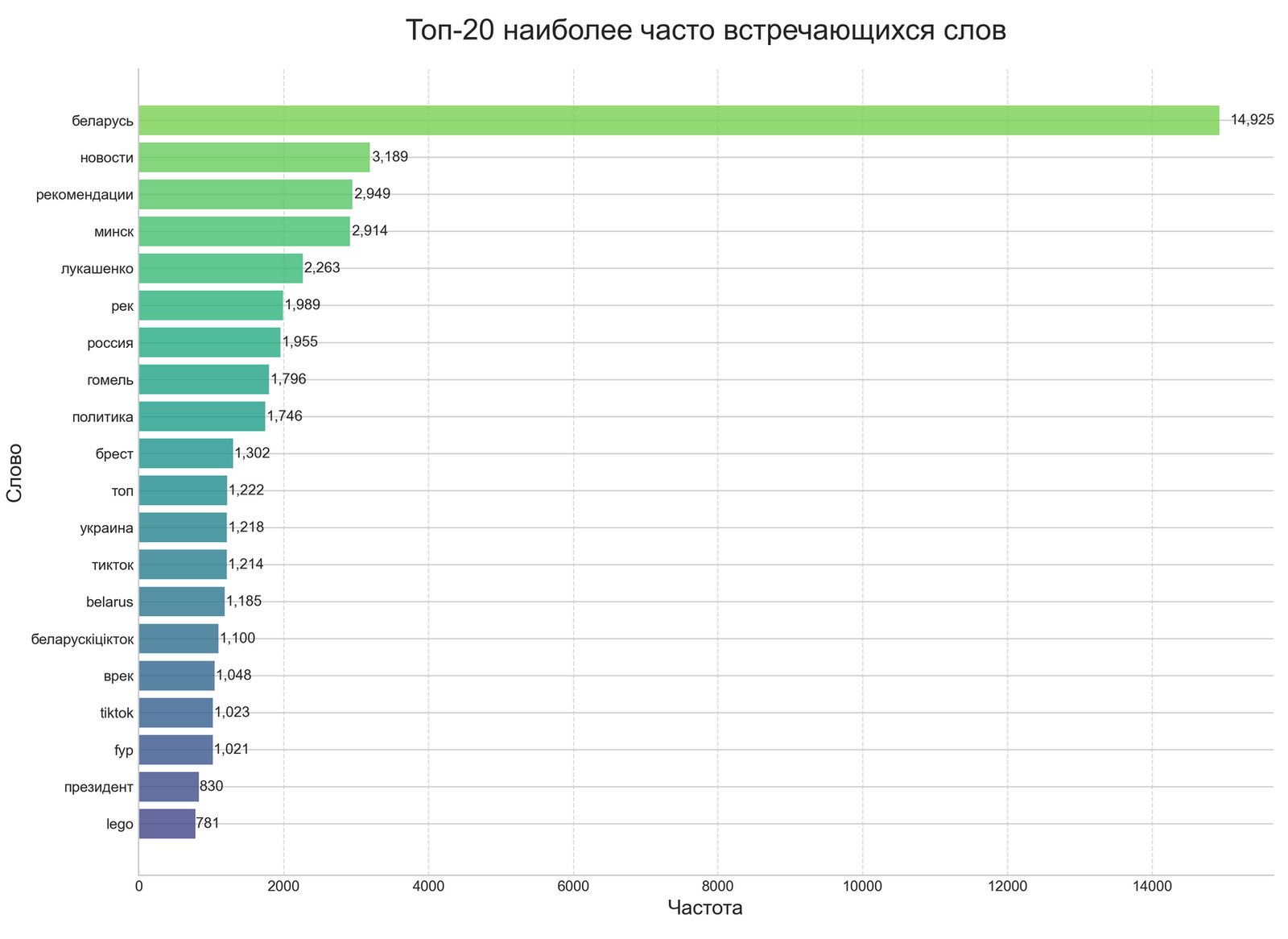

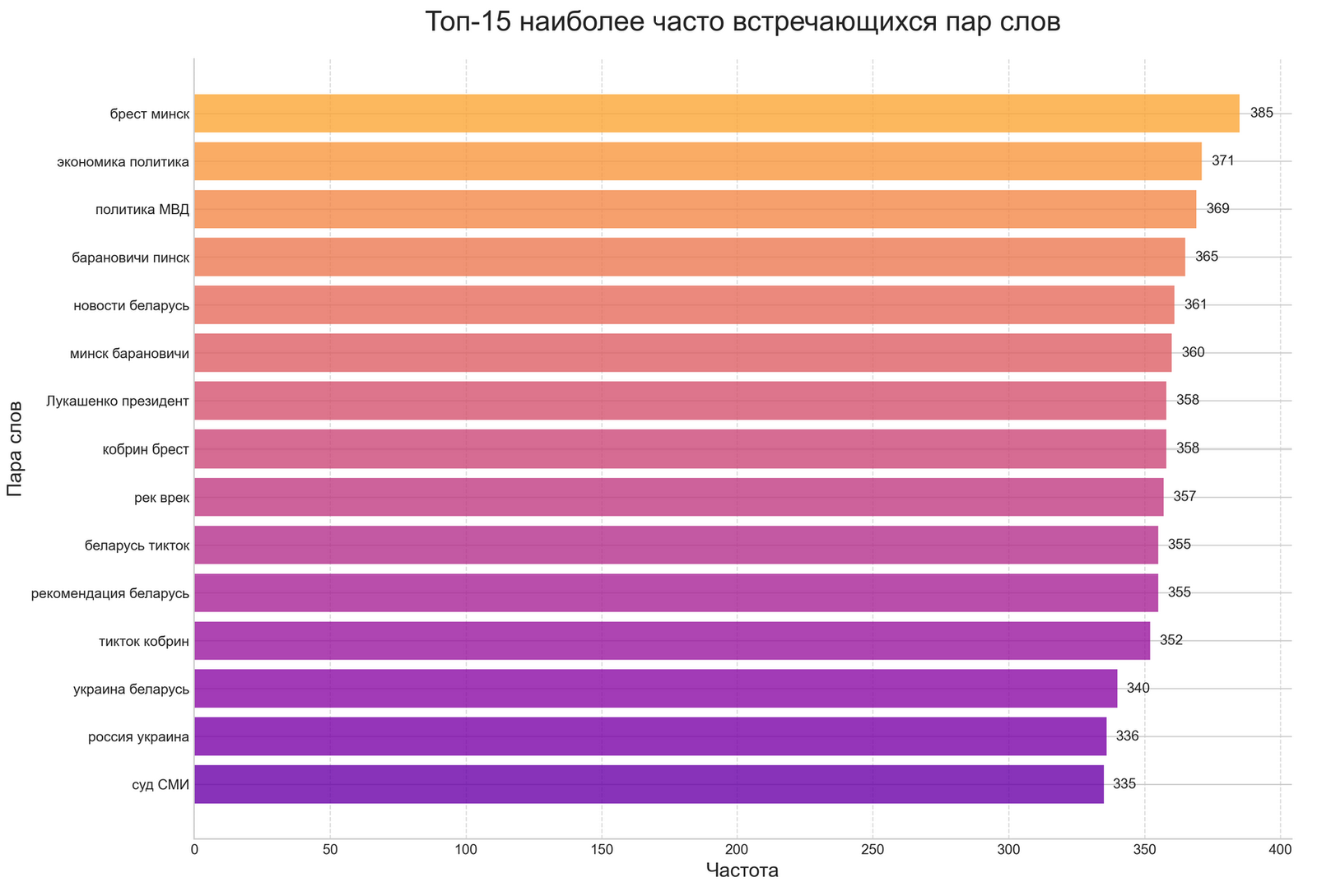
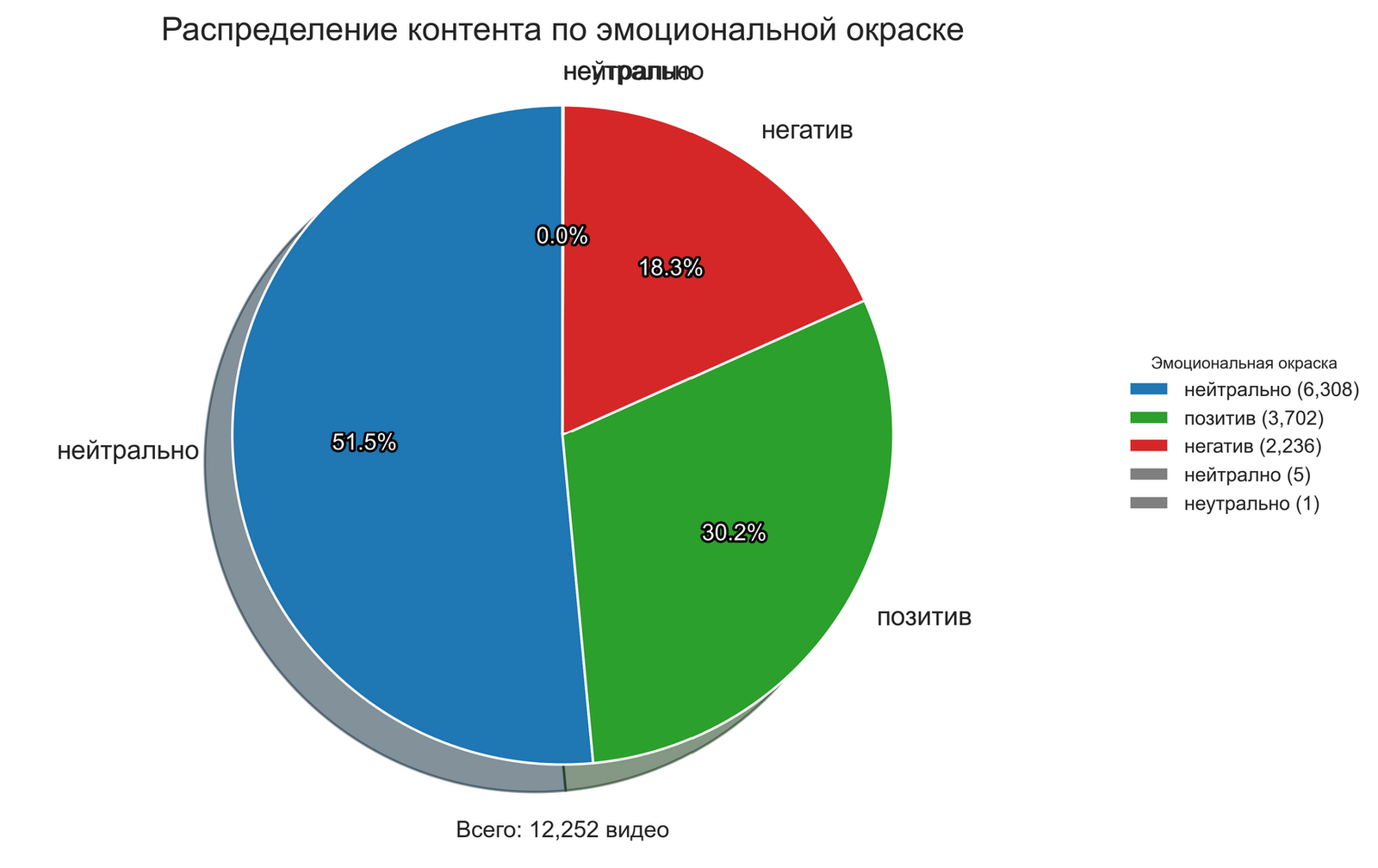





Інтэрпрэтацыя вынікаў: што паказалі два розныя метады?
Такія значныя разыходжанні ў выніках двух метадаў патрабуюць старанага аналізу і інтэрпрэтацыі.
Рознае разуменне “эмацыйнасці” тэксту праяўляецца ў тым, што NLTK-падыход вызначае эмацыйную афарбоўку на аснове прысутнасці канкрэтных слоў-маркераў з загадзя вызначанага слоўніка, без уліку кантэксту іх ужывання. Слова “вайна” аўтаматычна класіфікуецца як негатыўнае, незалежна ад кантэксту, што прыводзіць да завышанай ацэнкі негатыўнасці пры аналізе палітычных тэм. OpenAI-падыход ацэньвае эмацыйную афарбоўку на аснове больш комплекснага разумення тэксту, здольны адрозніваць нюансы і адценні значэнняў у пэўным кантэксце.
Прыклад з нашага корпуса дадзеных: “Беларусь: навіны рэгіёна, палітычная сітуацыя, аналітычныя матэрыялы”. NLTK класіфікуе гэты тэкст як негатыўны з-за прысутнасці палітычнай тэматыкі, тады як OpenAI можа класіфікаваць яго як нейтральны, улічваючы інфармацыйную, а не ацэначную прыроду кантэнту.
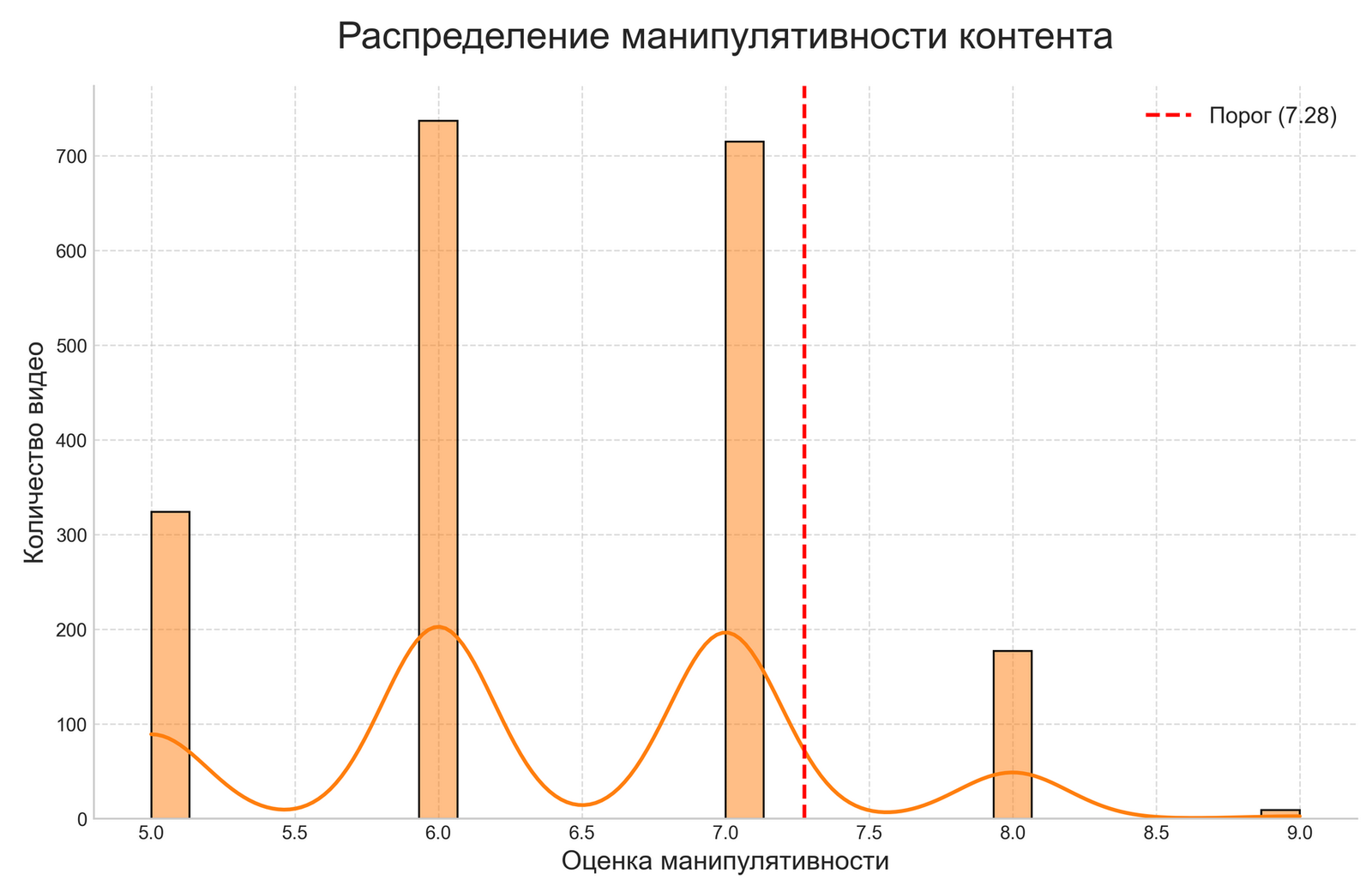
Розныя канцэпцыі “маніпулятыўнасці” праяўляюцца ў тым, што NLTK-падыход вызначае маніпулятыўнасць праз спрошчаную матэматычную формулу, заснаваную на колькасных суадносінах эмацыйна афарбаваных слоў. OpenAI-падыход ацэньвае маніпулятыўнасць на аснове больш складанага аналізу, які ўлічвае рытарычныя прыёмы, лагічныя структуры і іншыя прыкметы маніпуляцыі, якія просты слоўнікавы падыход можа не ўлавіць.
Істотную ролю ў такім драматычным разыходжанні вынікаў адыгрывае палітычны кантэкст кантэнту з хэштэгам #беларусь. NLTK, які абапіраецца на слоўнікі эмацыйных маркераў, схільны класіфікаваць палітычную тэматыку як негатыўную з-за часта сустракаемых тэрмінаў, звязаных з канфліктамі, уладай, супрацьстаяннем. OpenAI, які мае больш развітае разуменне кантэксту, здольны адрозніваць нейтральнае інфармацыйнае асвятленне ад эмацыйна афарбаванай прапаганды.
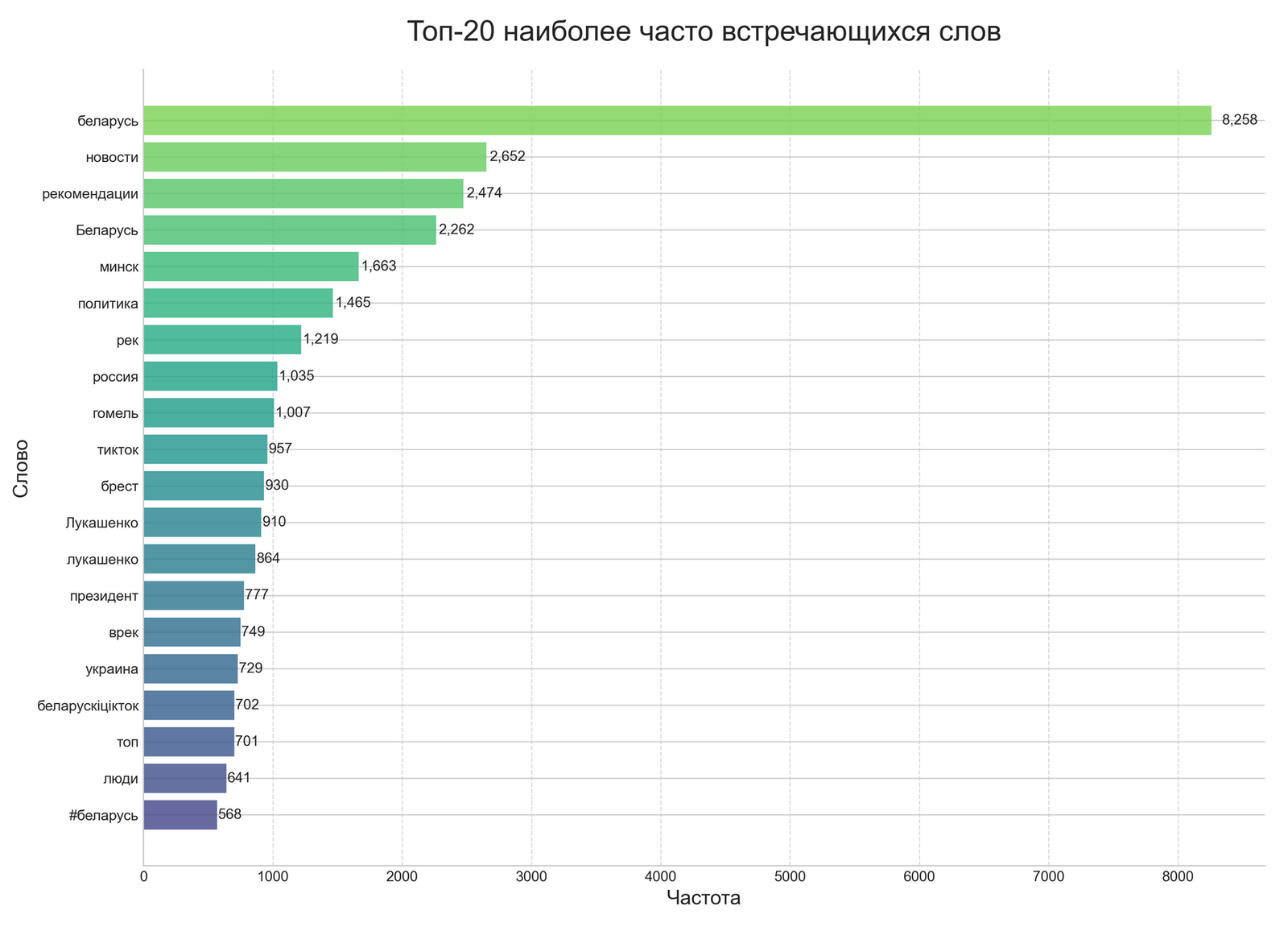
Інтэрпрэтацыя вынікаў: што паказалі два розныя метады?
Столь значныя разыходжанні ў выніках двух метадаў патрабуюць старанага аналізу і інтэрпрэтацыі.
Рознае разуменне “эмацыйнасці” тэксту праяўляецца ў тым, што NLTK-падыход вызначае эмацыйную афарбоўку на аснове прысутнасці канкрэтных слоў-маркераў з загадзя вызначанага слоўніка. Слова “вайна” аўтаматычна класіфікуецца як негатыўнае, “перамога” — як пазітыўнае, незалежна ад кантэксту. OpenAI-падыход ацэньвае эмацыйную афарбоўку на аснове сукупнага разумення тэксту, уключаючы кантэкст, падтэкст і схаваныя сэнсы. Фраза “чарговая бліскучая перамога” можа быць распазнана як іронія і класіфікавана як негатыўная.
Прыклад з нашага корпуса дадзеных: “Беларусь: навіны рэгіёна, палітычная сітуацыя, аналітычныя матэрыялы”. NLTK класіфікуе гэты тэкст як нейтральны, паколькі ў ім няма відавочных эмацыйных маркераў. OpenAI можа класіфікаваць яго як патэнцыйна негатыўны, улічваючы кантэкст палітычных навін у бягучай сітуацыі.
Розныя канцэпцыі “маніпулятыўнасці” праяўляюцца ў тым, што NLTK-падыход вызначае маніпулятыўнасць праз матэматычную формулу, заснаваную на суадносінах негатыўных і пазітыўных слоў. Гэты падыход мяркуе, што маніпулятыўны кантэнт — гэта пераважна негатыўны кантэнт. OpenAI-падыход ацэньвае маніпулятыўнасць на аснове складанага разумення рытарычных прыёмаў, лагічных памылак, эмацыйнага ціску, скажэння фактаў і іншых прыкмет маніпуляцыі, якія могуць прысутнічаць нават у фармальна пазітыўным або нейтральным тэксце.
Істотную ролю ў такім драматычным разыходжанні вынікаў можа адыгрываць палітычны кантэкст кантэнту з хэштэгам #беларусь. Вялікая моўная мадэль, навучаная на велізарным корпусе тэкстаў, уключаючы навінавыя і аналітычныя матэрыялы, можа “разумець” складаны палітычны кантэкст і ўлоўліваць схаваныя сэнсы і падтэксты, звязаныя з асвятленнем палітычнай сітуацыі ў рэгіёне.
Што гэта значыць для фактчэкінгу і медыяграматнасці
Выяўленыя разыходжанні паміж двума падыходамі маюць сур’ёзныя наступствы для працы фактчэкераў і даследчыкаў медыя.
Метадалагічныя выклікі ўключаюць праблему “залатога стандарту”, гэта значыць пытанне аб тым, які з метадаў бліжэй да ісціны, пры гэтым цалкам верагодна, што ісціна знаходзіцца недзе пасярэдзіне або патрабуе прынцыпова іншага падыходу; суб’ектыўнасць ацэнак, калі нават прасунутыя алгарытмы адлюстроўваюць суб’ектыўныя ўяўленні аб тым, што лічыць маніпуляцыяй, а што — легітымным перакананнем; кантэкстуальную залежнасць, якая праяўляецца ў тым, што ацэнка маніпулятыўнасці моцна залежыць ад культурнага, сацыяльнага і палітычнага кантэксту, што ўскладняе стварэнне ўніверсальных алгарытмаў.
На аснове нашага даследавання мы рэкамендуем фактчэкінгавым арганізацыям ужываць трыянгуляцыю метадаў, выкарыстоўваючы некалькі розных алгарытмічных падыходаў для праверкі ўзгодненасці вынікаў; наладжваць парогавыя значэнні, калібруючы парог “маніпулятыўнасці” на аснове экспертнай ацэнкі выбаркі кантэнту; укараняць чалавечы кантроль, паколькі аўтаматычныя сістэмы павінны выступаць інструментам падтрымкі рашэнняў экспертаў, а не іх заменай; улічваць моцныя бакі розных падыходаў, прымаючы пад увагу, што NLTK-падыход дае больш збалансаваную ацэнку эмацыйнай афарбоўкі, а OpenAI-падыход можа быць карысны для выяўлення схаваных маніпулятыўных тэхнік; адаптаваць тэхналогіі пад лакальны кантэкст, распрацоўваючы спецыялізаваныя слоўнікі эмацыйных маркераў для канкрэтных тэм і моў; забяспечваць празрыстасць метадалогіі, публічна раскрываючы ўжываныя метады аналізу і іх абмежаванні пры публікацыі вынікаў фактчэкінгу.
Вынікі нашага даследавання падкрэсліваюць неабходнасць навучання шырокай аўдыторыі распазнаванню розных тыпаў маніпуляцый, якія выходзяць за рамкі яўна негатыўнага эмацыйнага афарбоўвання; развіцця крытычнага мыслення і навыкаў аналізу медыякантэнту; разумення, што аўтаматычныя сістэмы аналізу, уключаючы прасунутыя ШІ-мадэлі, маюць свае абмежаванні і перадузятасці.
Тэхнічная ацэнка двух падыходаў: кошт, маштабаванасць, даступнасць
Для прыняцця абгрунтаваных рашэнняў аб укараненні тэхналогій важна ўлічваць не толькі іх дакладнасць, але і практычныя аспекты выкарыстання.
У галіне кошту і рэсурсаў NLTK-падыход з’яўляецца цалкам бясплатным, выкарыстоўвае толькі адкрытае ПЗ, працуе лакальна без падключэння да інтэрнэту, патрабуе ўмераныя вылічальныя рэсурсы, а апрацоўка 12,252 відэа заняла каля 20 хвілін. OpenAI-падыход патрабуе аплаты API-запытаў (прыблізны кошт аналізу нашага корпуса ~$100-150), залежыць ад стабільнага інтэрнэт-злучэння, стварае мінімальную нагрузку на лакальныя рэсурсы, а апрацоўка таго ж аб’ёму дадзеных заняла каля 1-2 гадзін з улікам затрымак API.
У плане маштабаванасці і прадукцыйнасці NLTK-падыход лёгка маштабуецца для апрацоўкі вялікіх аб’ёмаў дадзеных, яго прадукцыйнасць можна павялічыць за кошт паралельнай апрацоўкі, а хуткасць апрацоўкі прама прапарцыйная даступным вылічальным рэсурсам. OpenAI-падыход абмежаваны квотамі і хуткасцю API, яго маштабаванне павышае кошт прапарцыйна аб’ёму дадзеных, патрабуецца кіраванне чэргамі запытаў і апрацоўка памылак.
Гнуткасць і магчымасць наладкі ў NLTK-падыходзе праяўляецца ў поўнай празрыстасці і наладжвальнасці, магчымасці мадыфікаваць слоўнікі эмацыйных маркераў, змяняць алгарытмы такенізацыі і формулы ацэнкі, але патрабуецца экспертыза ў Python і NLP для істотных мадыфікацый. OpenAI-падыход прапануе абмежаваныя магчымасці наладкі праз промпт-інжынірынг, унутраная праца мадэлі непразрыстая (чорны ящык), мадэль рэгулярна абнаўляецца правайдэрам, што можа ўплываць на вынікі, але не патрабуе глыбокай тэхнічнай экспертызы для базавага выкарыстання.
У аспекце даступнасці і патрабаванняў да інфраструктуры NLTK-падыход працуе на любым камп’ютары з Python, не патрабуе спецыялізаванага абсталявання, можа быць разгорнуты ў ізаляванай сетцы і падыходзіць для апрацоўкі канфідэнцыйных дадзеных. OpenAI-падыход патрабуе пастаяннага падключэння да інтэрнэту, дадзеныя адпраўляюцца на серверы трэцяга боку, можа быць абмежаваны геапалітычнымі фактарамі і не падыходзіць для апрацоўкі строга канфідэнцыйнай інфармацыі.
Практычныя сцэнарыі прымянення: калі які падыход лепш
На аснове нашага параўнальнага аналізу можна вылучыць аптымальныя сцэнарыі выкарыстання для кожнага падыходу.
OpenAI-падыход аптымальны для больш збалансаванай ацэнкі эмацыйнай афарбоўкі кантэнту, асабліва пры працы з палітычна афарбаванымі тэмамі; для паглыбленага аналізу складанага кантэнту, пры расследаванні вытанчаных інфармацыйных кампаній, для выяўлення схаваных маніпуляцый і падтэкстаў, пры працы з кантэнтам, які патрабуе разумення культурнага кантэксту; для арганізацый з абмежаванай тэхнічнай экспертызай, калі няма ўласных спецыялістаў па NLP, пры неабходнасці хуткага запуску аналітычнай сістэмы.
NLTK-падыход аптымальны для першаснага скрынінгу вялікіх аб’ёмаў дадзеных з мэтай выяўлення патэнцыйна негатыўнага кантэнту, які патрабуе далейшага аналізу; для працы ва ўмовах абмежаванага доступу да сеткі, у рэгіёнах з нестабільным інтэрнэт-злучэннем, у арганізацыях з строгімі палітыкамі інфармацыйнай бяспекі, пры працы з канфідэнцыйнымі або адчувальнымі дадзенымі; для стварэння спецыялізаваных рашэнняў, калі патрабуецца дакладная наладка пад канкрэтную тэматыку або мову, пры неабходнасці поўнага кантролю над алгарытмам, для інтэграцыі ў існуючыя сістэмы маніторынгу. Пры гэтым варта ўлічваць тэндэнцыю гэтага метаду да класіфікацыі большасці палітычнага кантэнту як негатыўнага.
Гібрыдны падыход рэкамендуецца для прафесійных фактчэкінгавых арганізацый – выкарыстанне NLTK для першаснага выяўлення патэнцыйна праблемнага кантэнту з наступным больш глыбокім аналізам з дапамогай OpenAI для больш збалансаванай ацэнкі, завяршаемай экспертнай ацэнкай для выніковых высноў і публікацый; для даследчых цэнтраў і аналітычных агенцтваў – параўнальны аналіз вынікаў розных падыходаў, камбінаванне колькасных і якасных метадаў, распрацоўка новых метрык і метадалогій на аснове лепшых практык абодвух падыходаў.
Гібрыдны падыход рэкамендуецца для прафесійных фактчэкінгавых арганізацый – NLTK для першаснага скрынінгу і адбору падазронага кантэнту, OpenAI для паглыбленага аналізу адабраных матэрыялаў, экспертная ацэнка для выніковых высноў і публікацый; для даследчых цэнтраў і аналітычных агенцтваў – параўнальны аналіз вынікаў розных падыходаў, камбінаванне колькасных і якасных метадаў, распрацоўка новых метрык і метадалогій на аснове лепшых практык абодвух падыходаў.
Заключэнне і перспектывы развіцця аўтаматызаванага аналізу медыякантэнту
Наша даследаванне наглядна дэманструе, што аўтаматызаваны аналіз медыякантэнту знаходзіцца на ростанях традыцыйных алгарытмічных падыходаў і новых магчымасцяў штучнага інтэлекту. Кожны метад мае свае моцныя і слабыя бакі, і ідэальнага рашэння, прыдатнага для ўсіх задач, не існуе.
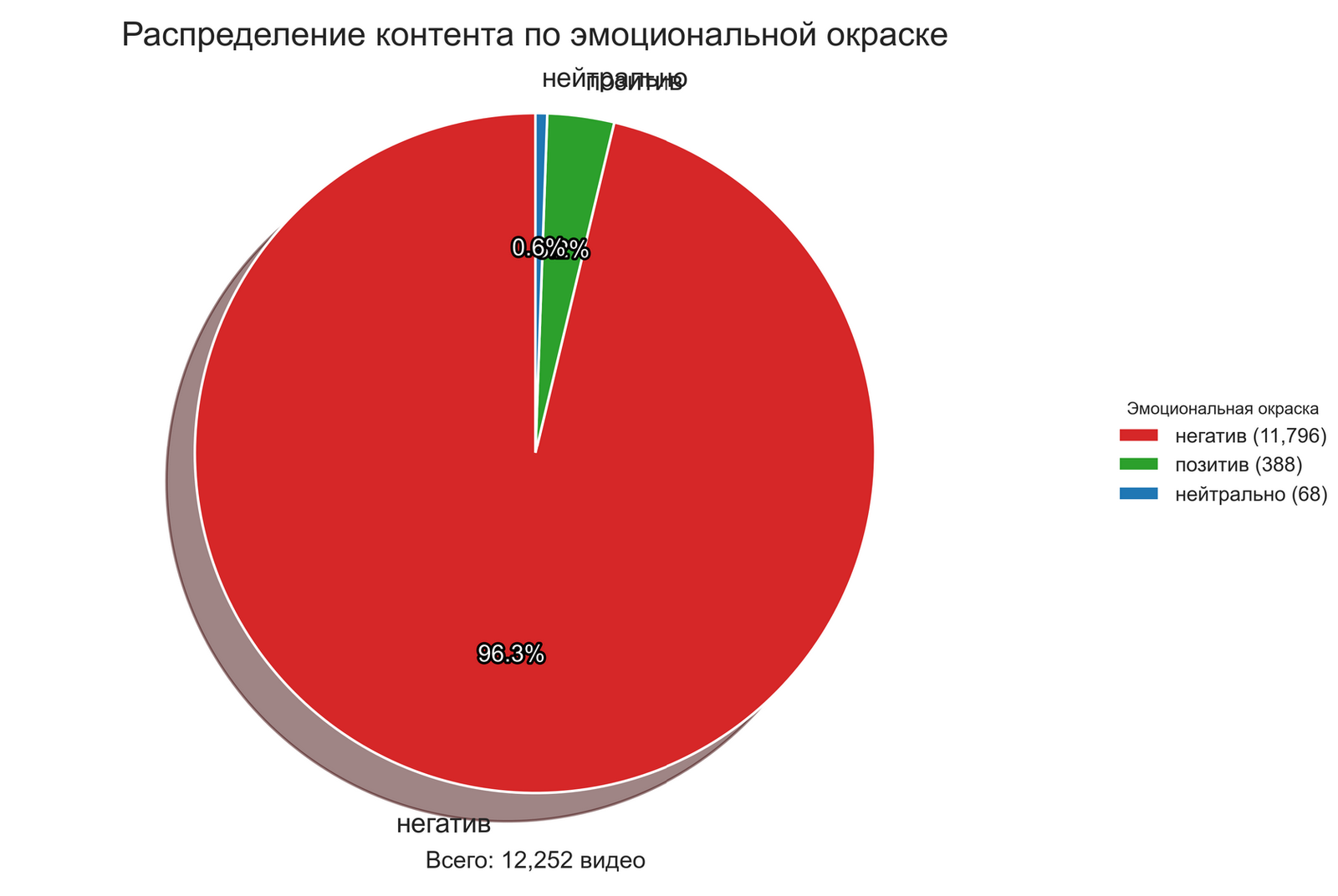
Драматычная розніца ў выніках ацэнкі аднаго і таго ж корпуса дадзеных двума рознымі метадамі падкрэслівае неабходнасць крытычнага стаўлення да аўтаматызаваных інструментаў аналізу. Асабліва паказальна, што NLTK-метад класіфікаваў пераважную большасць кантэнту (96.3%) як негатыўны, у той час як OpenAI-метад даў больш збалансаваную ацэнку з перавагай нейтральнага кантэнту (51.5%).
Гэтае разыходжанне дэманструе, наколькі моцна вынікі аналізу могуць залежаць ад выбранага метаду, што мае сур’ёзныя наступствы для даследчыкаў медыяпрасторы і фактчэкераў. Пры выкарыстанні аўтаматызаваных сістэм для маніторынгу медыякантэнту неабходна ўсведамляць магчымую перадузятасць алгарытмаў і прымаць яе пад увагу пры інтэрпрэтацыі вынікаў.
Ні адзін алгарытм не можа замяніць экспертную ацэнку і крытычнае мысленне, але пісьменнае прымяненне тэхналогій можа істотна павысіць эфектыўнасць працы фактчэкераў і даследчыкаў медыя. Найбольш прадуктыўным падыходам уяўляецца камбінаванне розных метадаў аналізу з наступнай экспертнай ацэнкай вынікаў.
У бліжэйшыя гады мы, верагодна, убачым развіццё некалькіх напрамкаў: спецыялізаваных мадэляў для аналізу медыякантэнту, навучаных на прыкладах маніпулятыўных тэхнік; лакальных варыянтаў вялікіх моўных мадэляў, якія не патрабуюць адпраўкі дадзеных на знешнія серверы; інтэрактыўных інструментаў, якія спалучаюць аўтаматычны аналіз з экспертнай ацэнкай; адукацыйных платформаў, якія выкарыстоўваюць ШІ для навучання грамадзян медыяграматнасці.
Незалежна ад тэхналагічнага прагрэсу, ключавым фактарам поспеху застанецца чалавечая экспертыза, крытычнае мысленне і прыхільнасць высокім этычным стандартам у барацьбе з дэзінфармацыяй і маніпуляцыямі. Аўтаматызаваныя сістэмы павінны разглядацца як інструменты падтрымкі прыняцця рашэнняў, а не як замена экспертнай ацэнцы.







